

We are moving everything to the new site. Please visit our new Stata page. This site will no longer be updated.

A workflow is the framework of conducting the data analysis. There is no single standard practice, but it usually involves the following steps: planning and documentation, cleaning data, analyzing data, presenting the results, and archiving. In each step, standardization and automation is the key to a good workflow.
Why is the workflow important? An effective workflow would save us a lot of time, trouble, and sometimes even our lives. We will want a workflow that is efficient for reproducing our work, group collaboration, and debugging; an efficient workflow would also keep us away from annoying retractions.
More on workflow in data analysis with Stata:
J. Scott Long (2009), The Workflow of Data Analysis Using Stata, Stata Press
The five main windows in Stata are Review, Results, Variables, Properties and Command.
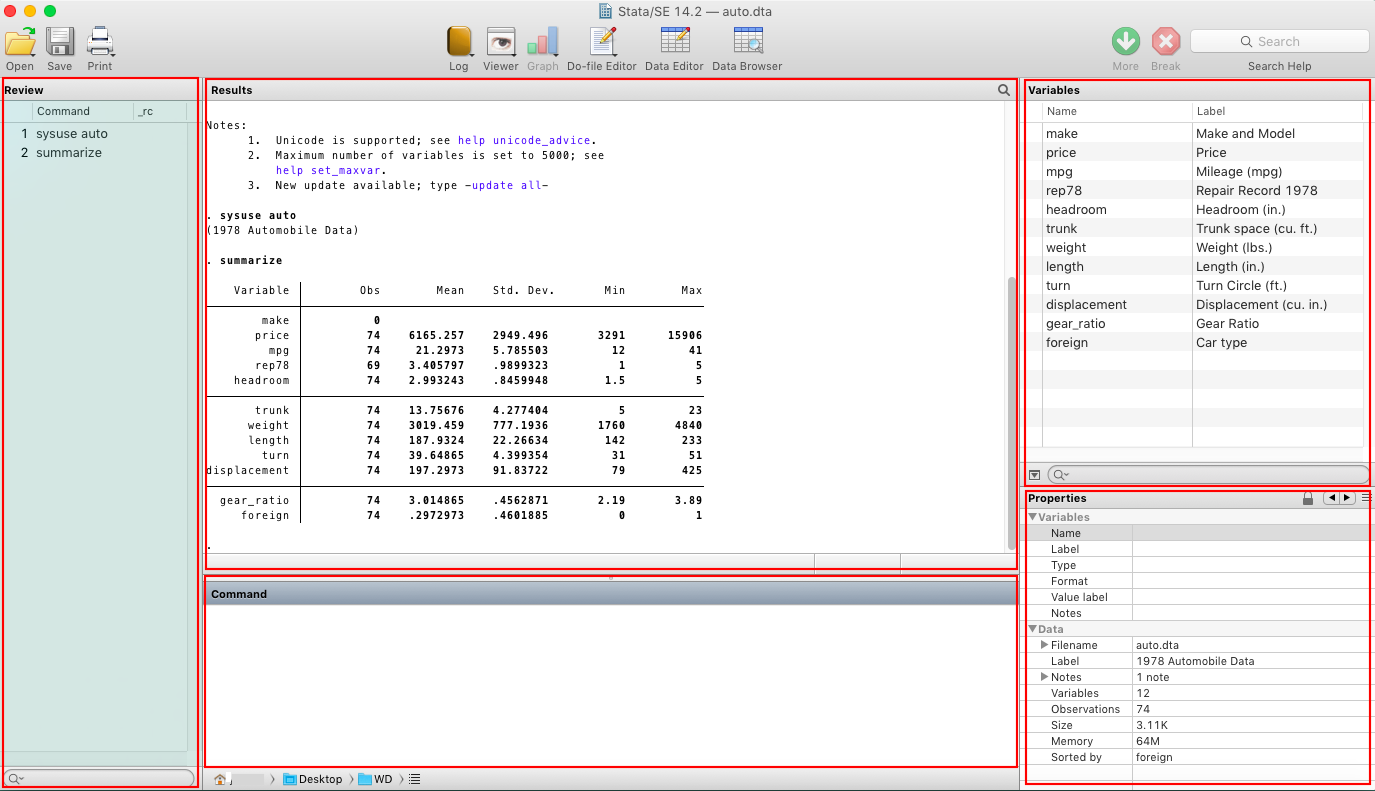
The Review window shows the history of commands, both the successful ones and the errors indicated by “_rc”, the error codes.
The Results window displays the past commands and the textual results.
The Variables window lists the variables’ names and their labels.
The Properties window, by definition, summarizes the various properties of a variable.
The current working directory is shown below the Command window. The little menu icon offers a way to change the working directory without being specified by the command cd. We will talk about the working directory shortly.
The Toolbar on top of the Results window gives us easy access to several features, most of which are self-explanatory.
Type help command to look for the syntax and usage of a command.
Type search keyword to 1) search a topic in Stata’s local keyword databases and the net materials; 2) if we do not know the exact command name; or 3) if we want to search for a user-written package to download.
For simple tasks and for exploratory purposes one can use Stata interactively by selecting and clicking the commands from the menu bar, or typing commands line-by-line in the Command window. However, for any reproducible work we will want to keep track of the codes and methods we use. To that end below are the very first steps.
A working directory is the default directory where Stata reads and writes files. Usually for each project we will want to set up a different working directory. We will set the current working directory to where we work with the project before we get started.
cd changes the working directory.
. cd ~/Desktop/WD/
If the working directory is not specified, in Mac simply typing cd sets the home directory as the current working directory.
If the directory contains spaces, we need to include quotes.
. cd "~/Desktop/WD/my folder/"
cd.. changes the working directory one level up.
pwd displays the path of the current working directory.
dir or ls lists the files in the current working directory.
sysuse dir lists the names of the datasets installed with Stata and any other datasets in the working directory.
A log file is a record of what we did with Stata in a session, including all the commands and outputs.
log using filename.log, text replace starts logging.
The replace option tells Stata to overwrite the log file if a log file with the same name already exists.
The text option saves the log file in plain text format which can be read by any text editor.
If the file is not specified to be a .log file, Stata will save it as Stata Markup and Control Language (SMCL) that can be read only by Stata’s Viewer.
log using filename.log, append appends the outputs from the current session to the ones from the last session.
Stata comes with its own text editor, the Do-file editor. A do-file is a text file where we keep, edit and save our commands.
To open the do-file editor, type doedit or click the Do-file Editor icon on the tool bar. To run the commands click Do on the top right.
We can also choose our own external editor. However, Microsoft Word, or any other word processor, is generally not recommended since it always tries to format the texts and could possibly distort the syntax and crash our codes.
More on a comprehensive review of the text editors specifically for Stata:
N. J. Cox, Some notes on text editors for Stata users
*
Usually a do-file should start with the following commands:
version 14
clear
capture log close
set more off
version specifies the version of Stata we use. Why bother doing that? Because Stata keeps upgrading itself, and programs written in older versions may not run in later versions. Specifying the current version will ensure that future versions will continue to interpret the codes correctly.
clear removes data and value labels from the memory before Stata can read another file. Stata works with one dataset at a time in memory.
capture log close closes the open log file if we have one and ignores this line if we do not, just to prevent the programs run in the current session from being logged to the last session's log file. capture ignores errors, if we have any, and allows the do-file or program to continue despite errors; thus capture log close will tell Stata to continue even if we do not have an open log file from the last session.
set more off tells Stata to run the commands continuously without worrying about the capacity of the Results window to display the results. Otherwise Stata will pause each time the screen is full, unless we keep hitting --more-- at the bottom of the Results window.
*
Do-files can run other do-files. If we are working with a project that involves several tasks, we will probably have several do-filed with each doing one task and have a master do-file running all the task-specific do-files. We can call other do-files from a master do-file:
do cleaning.do
do models.do
do graph.do
...
Reading and writing Stata binary files is much faster than using text files, among other advantages in data management. We may want to work with a file in Stata format as early as possible.
Stata will always go to the current working directory when working with files.
use filename, clear loads a Stata file (.dta) from the current working directory. clear clears the memory for Stata to load a new file. If the workspace is already clear, we can skip that as well.
save filename, replace saves a Stata file to the current working directory. replace overwrites the file saved earlier with the same file name. If such a file does not exist, we can skip the replace option.
To load a file located in a subdirectory under the working directory, we need to specify the relative path.
. use folder/mydata.dta, clear
To tell Stata to read a file elsewhere, we need to specify a full path.
. use ~/elsewhere/mydata.dta, clear
We can also read a file over the Internet.
. use http://www.stata-press.com/data/r14/auto, clear
sysuse loads example datasets installed with Stata
. sysuse auto, clear
import/export delimited reads/saves text-delimited files. The data can be tab-separated (often .txt) or comma-separated (.csv). If the extension is not specified, Stata assumes that it is a .csv file.
. import delimited filename, clear
. import delimited var1 var2 var3 using filename.csv, clear
loads the dataset and names the three variables var1, var2 and var3.
. export delimited output.txt, delimiter(tab) exports a file and saves it as a tab-delimited text file.
Sometimes we need to take a few more steps to read a text file. Let's look at a real case.
Let's say we have a text file downloaded from a database and we tried to read it into Stata by
. import delimited output.txt
. list in 1/10
+-------------------------------------------------------------------------------------------+
| v1 |
|-------------------------------------------------------------------------------------------|
1. | |
2. | .. |
3. | |
4. | ticker evtdate car |
5. | EGAS 12FEB2014 0.02356 |
|-------------------------------------------------------------------------------------------|
6. | EGAS 27JUL2012 -0.00276 |
7. | HGR 03JUL2002 0.01478 |
8. | HGR 03MAY2005 -0.05070 |
9. | HGR 05AUG2002 0.02337 |
10. | HGR 20JAN2004 0.04206 |
+-------------------------------------------------------------------------------------------+
We can see that all variables are squeezed into one column "v1", that there are empty rows, and that the variable names actually are the fourth row. To fix those problems, first let's try
. import delimited output.txt, rowrange(4:l) varnames(4) delimiters(space)
. list ticker-car in 1/5
rowrange(4:l) reads data from the fourth to the last row (l stands for "last"). varnames(4) means the fourth row is for the variable names. delimiters(space) tells Stata to use space as the delimiters.
+--------------------------------------------------------------------------------------------------------+
| ticker v2 v3 v4 v5 v6 evtdate v8 v9 v10 v11 v12 v13 car |
|--------------------------------------------------------------------------------------------------------|
1. | EGAS . . . . 12FEB2014 . .02356 . |
2. | EGAS . . . . 27JUL2012 -.00276 . . |
3. | HGR . . . . 03JUL2002 . . .01478 |
4. | HGR . . . . 03MAY2005 . -.0507 . |
5. | HGR . . . . 05AUG2002 . . .02337 |
+--------------------------------------------------------------------------------------------------------+
Now the first few empty rows have been removed; and (some) variables are properly named. However, there was something not right. We had three variables, and now we've got a lot more (260! if we list them all). What happened? Stata used multiple spaces as delimiters, and due to that values from one variable went to different columns.
Here is what we want to do:
. import delimited output.txt, rowrange(4:l) varnames(4) delimiters(space, collapse)
Here delimiters(space, collapse) collapsed the multiple spaces into just one.
. list in 1/5
+----------------------------------------+
| ticker evtdate car v4 |
|----------------------------------------|
1. | EGAS 12FEB2014 .02356 |
2. | EGAS 27JUL2012 -.00276 |
3. | HGR 03JUL2002 .01478 |
4. | HGR 03MAY2005 -.0507 |
5. | HGR 05AUG2002 .02337 |
+----------------------------------------+
Now it's about right. We got the correct variable names, just in the wrong places. We need to fix that.
. drop ticker
. rename evtdate ticker
. rename car evtdate
. rename v4 car
. list in 1/5
+------------------------------+
| ticker evtdate car |
|------------------------------|
1. | EGAS 12FEB2014 .02356 |
2. | EGAS 27JUL2012 -.00276 |
3. | HGR 03JUL2002 .01478 |
4. | HGR 03MAY2005 -.0507 |
5. | HGR 05AUG2002 .02337 |
+------------------------------+
Done.
import/export excel reads/saves worksheets from Microsoft Excel (.xls and .xlsx) files.
. import excel filename.xlsx, clear loads the dataset but the variable names will be lost. What we see are Excel's column names.
. import excel filename.xls, firstrow loads the dataset with the original variable names.
. export excel output.xlsx, firstrow(varlabels) sheet("output1") saves the dataset as an Excel file "output.xlsx" to the sheet "output1".
Stata can be used as a calculator interactively. display displays the results of expressions right away.
. display 100^2
1000010,000the square root of 10000 is 1003.14159270.69146246If you are shopping for datasets to play with, NYU Shanghai's Chinese Datasets Archive offers many datasets on a wide range of topics related to China.